第12课:正则表达式(1)
正则表达式(Regular Expressions)的功能,简单地理解就是通过模式(Pattern)来匹配(Match)文本内容,并对所匹配的内容进一步操作,如格式判断、替换、分割、删除等。
C#中的正则表达式
在.NET Framework类库中的System.Text.RegularExpressions命名空间中定义了一系列正则表达式操作资源,如Regex、Match、MatchCollection等类型。
进行简单测试时,可以使用Regex.IsMatch()方法,它需要两个参数,其中,参数一指定文本内容,参数二同样使用字符串类型指定匹配模式;当参数一的文本符合参数二的模式时,方法返回true值,否则返回false值。
下面的代码演示了Regex.IsMatch()方法的应用。
| C# |
using System;
using System.Text.RegularExpressions;
public partial class Test : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
string pattern = @"abc";
string s = "abcdefg";
bool result = Regex.IsMatch(s, pattern);
tWeb.WriteLine(result);
}
}
|
代码中,首先定义了一个简单的模式,只匹配abc;在字符串s中包含了abc,所以,Regex.IsMatch()方法会返回true。本例最终显示为True。
C#代码中定义模式字符串时,为更有效的定义模式内容,特别是需要通过\字符转义的内容,应使用逐字字符串,即使用@""定义模式字符串。
默认情况下,文本的匹配是区分字母大小写的,如果需要忽略字母大小写,可以在Regex.IsMatch()方法中使用第三个参数指定,如下面的代码。
| C# |
using System;
using System.Text.RegularExpressions;
public partial class Test : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
string pattern = @"abc";
string s = "ABCDEFG";
bool result = Regex.IsMatch(s, pattern,RegexOptions.IgnoreCase);
tWeb.WriteLine(result);
}
}
|
本例,如果Regex.IsMatch()方法没有使用第三个参数会显示False;这里使用RegexOptions.IgnoreCase枚举值指定忽略大小写,运行结果为True。
RegexOptions枚举的常用成员包括:
- IgnoreCase,不区分大小写。
- Multiline,多行模式。改变^和$的含义,分别指定在任意一行的行首和行尾匹配。在单行模式下,分别匹配文本的开始和结尾。
- Singleline,指定单行模式。更改圆点(.)的含义,它会匹配任何字符(包含\n换行符)。在多行模式下,圆点(.)匹配\n之外的所有字符。
- RightToLeft,从右向左搜索。
需要获取第一个匹配内容时,可以使用Regex对象中的Match()方法,如下面的代码。
| C# |
using System;
using System.Text.RegularExpressions;
public partial class Test : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
string pattern = @"abc";
string s = "abcdefg";
Match m = Regex.Match(s,pattern);
tWeb.WriteLine(m.Value);
}
}
|
本例,首先定义了模式pattern和文本内容s,然后调用Regex.Match()方法返回匹配的第一个结果,返回类型为Match类,使用其中的Value属性可以获取匹配的内容。代码执行结果会显示abc,即字符串s中的前三个字符。
如果文本中可能有多个匹配结果,可以使用Regex对象的Matches()方法返回全部匹配结果,如下面的代码。
| C# |
using System;
using System.Text.RegularExpressions;
public partial class Test : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
string pattern = @"abc";
string s = "abcdefgabcdefgabc";
MatchCollection mc = Regex.Matches(s,pattern);
foreach (Match m in mc)
{
tWeb.WriteLine(m.Value);
}
}
}
|
本例,字符串s中包含了三个abc,可以使用Regex.Matches()方法返回所有匹配的内容,返回结果为MatchCollection对象;代码最后使用foreach语句遍历所有结果,并通过Match对象的Value属性显示匹配内容。代码执行会显示三个abc。
Regex类中的Match()和Matches()方法还有一些重载版本,比如,可以指定开始匹配的字符索引位置,不指定时从第一个字符开始(索引0);还可以指定搜索的字符数,不指定时搜索从指定位置开始的所有内容。
Regex类中的Split()方法通过模式分隔文本内容,下面的代码演示了此方法的基本应用。
| C# |
using System;
using System.Text.RegularExpressions;
public partial class Test : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
string pattern = @",|\s";
string s = "abc,def ghi\tjkl";
string[] result = Regex.Split(s, pattern);
foreach(string r in result)
tWeb.WriteLine(r);
}
}
|
本例中,会将字符串s通过逗号(,)或空白字符(空格、制表符等)进行分割;代码运行结果如图1。
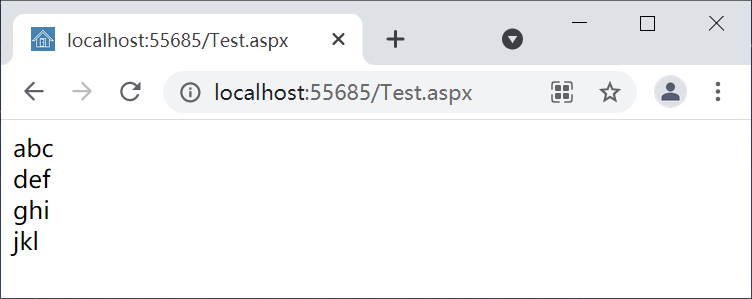
图1
Regex类中的Replace()方法会将文本中的匹配模式的内容替换为指定的内容,如下面的代码演示了此方法的基本应用。
| C# |
using System;
using System.Text.RegularExpressions;
public partial class Test : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
string pattern = @"abc";
string s = "abcdefgabc";
string result = Regex.Replace(s, pattern,"***");
tWeb.WriteLine(result);
}
}
|
代码的功能是将字符串s中的abc替换为***,结果会显示***defg***。
此外,还可以在Regex.Replace()方法中使用委托指定替换规则,如下面的代码。
| C# |
using System;
using System.Text.RegularExpressions;
public partial class Test : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
string pattern = @"abc";
string s = "abcdefgabc";
string result = Regex.Replace(s, pattern,(Match m)=> {
return "*" + m.Value + "*";
});
tWeb.WriteLine(result);
}
}
|
代码的功能是将字符串s中的abc前后各加一个星号(*),执行结果如图2。
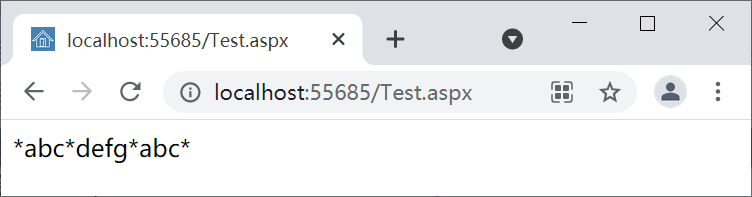
图2
Regex.Replace()方法中使用委托类型定义如下。
| C# |
[SerializableAttribute]
public delegate string MatchEvaluator(Match match)
|
其中,参数match会分别带入匹配结果,委托方法或Lambda表达式中需要返回匹配结果的操作结果,返回类型为string。如前面示例中就是在匹配内容和前面和后面各添加一个星号(*)。
本节主要讨论了C#代码中进行正则表达式操作的常用资源和基本应用方法,接下来会讨论更多关于模式的定义。
匹配字符
定义模式时,有一些字符会有特定的功能或含义,如图3。

图3
需要匹配文本中的单个字符应注意,对于特殊的字符,需要使用\字符进行转义,在C#中需要转义的字符包括 \ * + ? | { [ ( ) ^ $ . # 和空格。如果模式中包含了这些字符,可以先直接定义在字符串中,然后调用Regex.Escape()方法进行转义,如下面的代码。
| C# |
using System;
using System.Text.RegularExpressions;
public partial class Test : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
string pattern = @"*.*";
tWeb.WriteLine(Regex.Escape(pattern));
}
}
|
模式中定义的内容为*.*,通过Regex.Escape()方法转义后转换为\*\.\*,这也是本例的显示结果。
Regex.Escape()方法的反向操作可以使用Regex.Unescape()方法,如下面的代码会显示*.*。
| C# |
using System;
using System.Text.RegularExpressions;
public partial class Test : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
string pattern = @"\*\.\*";
tWeb.WriteLine(Regex.Unescape(pattern));
}
}
|
对于一些特殊的字符可以使用如下转义:
- \a,匹配响铃,字符编码\u0007。
- \b,两种应用场景,[\b ]匹配退格,字符编码\u0008。中括号之外,\b是匹配字边界。
- \t,匹配制表符,字符编码\u0009。
- \r,匹配回车,字符编码\u000D。
- \v,匹配垂直制表符,字符编码\u000B。
- \f,匹配换页符,字符编码\u000C。
- \n,匹配换行符,字符编码\u000A。
- \e,匹配转义ESC(Escape)符,字符编码\u001B。
- \nnn,匹配ASCII字符,nnn 包含表示八进制字符代码的两位数或三位数。
- \xnn,匹配ASCII字符,nn表示两位十六进制字符代码。
- \cX,匹配ASCII控制字符,其中X是控制字符的字母,如\cC表示Ctrl-C。
- \unnnn ,匹配的UTF-16代码单元,单元值是nnnn十六进制。
使用\后接无法识别的转义字符时,将匹配此字符,如\-和直接使用-都表示匹配-符号。
对特殊字符转义需要特别注意,在不使用逐字字符串时,C#中的字符串本身就包含了转义,如"\."表示的是圆点,如果需要在模式中转义圆点就应该写成"\\.",所以建议在定义模式时总是使用逐字字符串,如@"\."。如下面的代码用于匹配*.xlsx文件名。
| C# |
using System;
using System.Text.RegularExpressions;
public partial class Test : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
string pattern = @".\.xlsx$";
string filename = "demo1.xlsx";
tWeb.WriteLine(Regex.IsMatch(filename,pattern));
}
}
|
本例中定义的模式为.\.xlsx,其中,第一个圆点表示一个或多个字符,\.表示一个圆点,而\.xlsx则表示.xlsx扩展名,最后的$符号表示匹配的内容应该在文本的末尾,代码执行结果会显示True。这里,可以修改filename的内容来观察运行结果。
为避免转义带来的问题,也可以使用普通字符串定义模式,然后使用Regex.Escape()方法对需要转义的字符进行转换。
对于需要匹配的普通文本内容,可以直接使指定,匹配多个字符中的一个时,可以将这些字符定义在一对方括号中;匹配连续的数字或字母时,还可以在中括号中使用连接符(-)指定,如下面的代码。
| C# |
tWeb.WriteLine(Regex.IsMatch("aefg",@"[abcd]")); // True
tWeb.WriteLine(Regex.IsMatch("xyz", @"[abcd]")); // False
tWeb.WriteLine(Regex.IsMatch("aefg", @"[a-d]")); // True
tWeb.WriteLine(Regex.IsMatch("xyz", @"[a-d]")); // False
|
本例,前两个输出匹配a、b、c、d四个字母中的一个,后两个输出使用连接符,同样是匹配a到d的四个字母中的一个。
指定多组匹配规则时,使用竖线(|)分隔,如下面的代码。
| C# |
string p = @"[a-d|1-4]";
tWeb.WriteLine(Regex.IsMatch("aefg",p)); // True
tWeb.WriteLine(Regex.IsMatch("xyz", p)); // False
tWeb.WriteLine(Regex.IsMatch("1560", p)); // True
|
本例定义的模式为a到d的四个字母,或者是1到4的数字其中的一个字符。
在方括号定义的集合中,还可以使用^符号定义反向匹配,如判断文本中不应包含a和b时,可以使用如下代码。
| C# |
using System;
using System.Text.RegularExpressions;
public partial class Test : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
string pattern = @"[^ab]";
tWeb.WriteLine(Regex.IsMatch("a", pattern)); // False
tWeb.WriteLine(Regex.IsMatch("x", pattern)); // True
}
}
|
模式中,定义在一对中括号的集合最终会匹配一个字符,而定义在一对圆括号中的内容(子表达式)还可以定义更多的形式,如下面的代码。
| C# |
using System;
using System.Text.RegularExpressions;
public partial class Test : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
string pattern = @"(abc[0-9])(xyz[0-9])";
tWeb.WriteLine(Regex.IsMatch("abc1xyz1", pattern)); // True
tWeb.WriteLine(Regex.IsMatch("abcdxyz1", pattern)); // False
tWeb.WriteLine(Regex.IsMatch("abc1xyz", pattern)); // False
}
}
|
代码中定义的模式包含两个部分,前一部分由abc加一位数字组成,后一部分由xyz加一位数字组成。
匹配特定类型字符
匹配文本中某一类型的字符时,可以使用转义符或Unicode块。C#中可以使用如下限定符:
- \d,数字0到9,相当于[0-9]。因为完整的数字还可能包含正号(+)、负号(-)、小数点(.)等字符,所以在开发过程中,判断文本内容是否为有效的数字时,应使用第7课讨论的相关方法。
- \D,非数字字符,即0到9以外的字符。
- \s,空白字符,如空格、制表符、回车符、换行符等。
- \S,非空白字符,匹配与\s限定符相反的内容。
- \w,字母、数字和下画线字符。ECMAScript标准中相当于[a-zA-Z0-9_]。
- \W,字母、数字和下画线以外的字符。
下面的代码演示了\s限定符的应用。
| C# |
using System;
using System.Text.RegularExpressions;
public partial class Test : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
string pattern = @"\s";
tWeb.WriteLine(Regex.IsMatch(" ",pattern));
tWeb.WriteLine(Regex.IsMatch("\t", pattern));
}
}
|
执行代码会在页面中显示两个True,这里,\s限定符匹配了空格和水平制表符(\t)。
对于Unicode字符,可以按Unicode块进行匹配,格式为\p{<块名>}。Unicode字符集中,汉字的范围是4E00到9FFF,Unicode块名为IsCJKUnifiedIdeographs,代码中,判断字符是否为汉字可以使用如下模式。
| C# |
string pattern = @"\p{IsCJKUnifiedIdeographs}";
|
下面的代码,通过tStr.IsChinese()方法判断字符或字符串是否中文字符。
| C# |
// 是否为中文字符
public static bool IsChinese(this char ch)
{
string pattern = @"\p{IsCJKUnifiedIdeographs}";
return Regex.IsMatch(ch.ToString(), pattern);
}
// 字符串是否为中文
public static bool IsChinese(this string s)
{
char[] chars = s.ToCharArray();
for(int i = 0; i < chars.Length; i++)
{
if (chars[i].IsChinese() == false) return false;
}
return true;
}
|
代码中,tStr.IsChinese()定义为char和string类型的扩展方法,下面的代码演示了此方法的应用。
| C# |
using System;
public partial class Test : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
tWeb.WriteLine('A'.IsChinese()); // False
tWeb.WriteLine('好'.IsChinese()); // True
tWeb.WriteLine("Hello好".IsChinese()); // False
tWeb.WriteLine("您好".IsChinese()); // True
}
}
|
匹配数量
匹配文本内容时,还可以判断模式的匹配次数,相关的限定符如表。
| 贪婪限定符 | 惰性限定符 | 说明 |
|---|
| * | *? | 匹配零次或多次。 |
| + | +? | 匹配一次或多次。 |
| ? | ?? | 匹配零次或一次。 |
| {n} | {n}? | 匹配n次。 |
| {n,} | {n,}? | 匹配n次或更多次。 |
| {n,m} | {n,m}? | 匹配n到m次。 |
表中,数量n和m是正整数。使用贪婪限定符时,会尽可能多的特定模式实例。贪婪限定符后添加问号(?)时,匹配变为惰性的,会匹配尽可能少的实例。
下面的代码演示了+限定符的应用。
| C# |
using System;
using System.Text.RegularExpressions;
public partial class Test : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
string pattern = @"a+";
string s = "aaa";
foreach(Match m in Regex.Matches(s,pattern))
{
tWeb.WriteLine(m.Value);
}
}
}
|
代码中,限定符+属于贪婪限定符,本例中会尽可能多地匹配字母a,这样,匹配结果就是aaa,显示结果如图4(a);如果将代码中的模式修改为@"a+?"就会使用惰性匹配,此时会分别匹配三个字母a,执行结果如图4(b)。
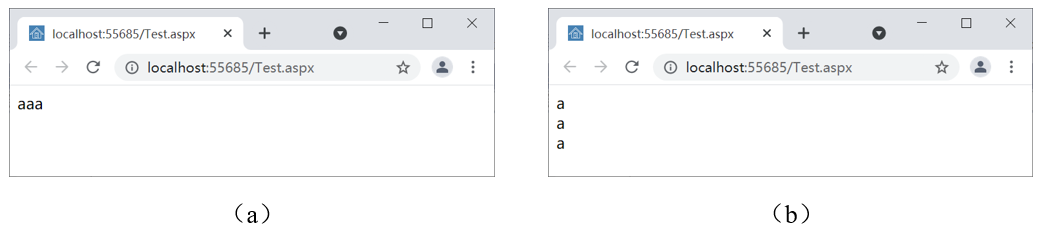
图4
位置和边界
前面已经讨论了如保匹配指定内容和数量,本节将讨论模式中如何定义匹配内容的位置及边界,相应的限定符包括:
- ^,在方括号定义的集合中定义为反向匹配,在方括号外使用时,默认情况下(单行模式)匹配文本开始的内容;在多行模式中匹配在每行开始的内容。
- $,默认情况下(单行模式)匹配文本结束位置的内容,或者是文本末尾的换行符(\n)之前;多行模式中必须出现在行的末尾,或在行末尾的 换行符(\n)之前。
- \A,匹配必须出现在文本开始位置的内容,与单行模式下的^限定符功能相同。
- \Z,匹配必须出现在文本末尾或末尾换行符(\n)之前的内容,与单行模式下的$限定符功能相同。在判断换行时,\Z与\n匹配,但与\r\n不匹配。
- \z,匹配必须出现在文本末尾的内容,但不匹配换行符(\n)。
- \G,从上一匹配结束位置开始匹配的内容。指定匹配必须出现在上一个匹配结束的位置。将此位置与Regex.Matches()或Match.NextMatch()方法配合使用时,它可确保所有匹配项是连续的。
- \b,匹配字边界。
- \B,匹配非字边界,与\b匹配规则相反。
下面的代码演示了如何匹配11位手机号码。
| C# |
using System;
using System.Text.RegularExpressions;
public partial class Test : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
string pattern = @"^1\d{10}$";
tWeb.WriteLine(Regex.IsMatch("12345678910", pattern)); // True
tWeb.WriteLine(Regex.IsMatch("23456789101", pattern)); // False
tWeb.WriteLine(Regex.IsMatch("1234567891", pattern)); // False
}
}
|
模式中,^1表示要使用数字1开始,\d{10}$表示以10位数字结束。
限定符\b用于匹配\w和\W的边界;\B定义非边界,与\b的匹配规则相反。下面的代码演示了\b限定符的基本应用。
| C# |
using System;
using System.Text.RegularExpressions;
public partial class Test : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
string pattern = @"\bgo\b";
tWeb.WriteLine(Regex.IsMatch("go", pattern)); // True
tWeb.WriteLine(Regex.IsMatch("gold", pattern)); // False
tWeb.WriteLine(Regex.IsMatch("let's go", pattern)); // True
}
}
|
代码的功能是检查文本中是否包含独立的单词go,而gold、good这样的单词是不会匹配的。
Web应用中,如果需要识别代码中的关键字时并使用特定的样式,使用\b限定符是很方便实现的,如下面的代码,会将关键字定义为span元素,并将元素的class属性设置为code_keyword。
| C# |
using System;
using System.Text.RegularExpressions;
public partial class Test : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
string keyword = @"int|for";
string pattern = @"\b" + keyword + @"\b";
string source = @"int sum = 0;
for(int i=1;i<=100;i++) {
sum+=i;
}
System.Console.WriteLine(sum);";
//
string result = Regex.Replace(source, pattern, (Match match) =>
{
return "<span class='code_keyword'>" + match.Value + "</span>";
});
tWeb.WriteLine("<pre>"+result+"</pre>");
}
}
|
接下来,需要在/Test.aspx页面中定义code_keyword类的样式,如下面代码style元素中定义的内容。
| HTML |
<head runat="server">
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"/>
<title></title>
<style>
.code_keyword{
font-weight:bold;
color:blue;
}
</style>
</head>
|
呈现的页面中,代码会显示在pre元素中,其中的int和for关键字会显示为蓝色并加粗,效果如图5。
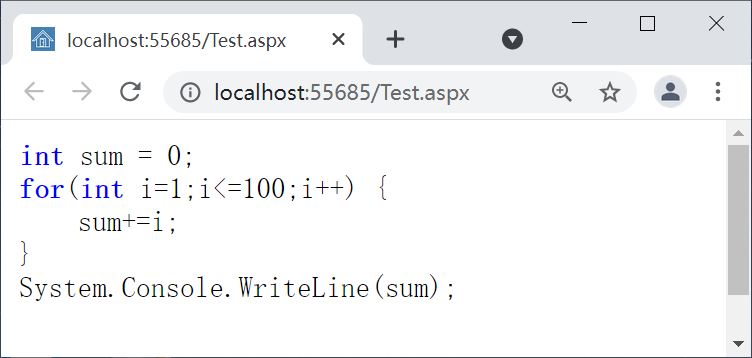
图5